简述
以微信朋友圈为例,当打开朋友圈的时候默认刷新最新的数据,数据流以时间倒序排序。那么这样的数据表现形式我们称之为时间线。需要注意的是
我们定义时间线的起始时间为账户的创建的时间,例如,A是B的粉丝,B账号创建时间为2018年10月1日,而A账户的创建时间为2018年11月1日则在A的时间线只可以看到2018年11月1日以后的数据。而B的时间线则是2018年10月1日开始往后的数据。也就是说我们以账号的创建时间为锚点。
场景
用户A是B的粉丝,则A订阅了B,B发布朋友圈则推送给A。
如上图所示,我们整理了一下订阅者关系如下:
1 | A (3) |
以空间换时间的存储方案
写入效率低,数据允余占用存储空间,读取效率高。
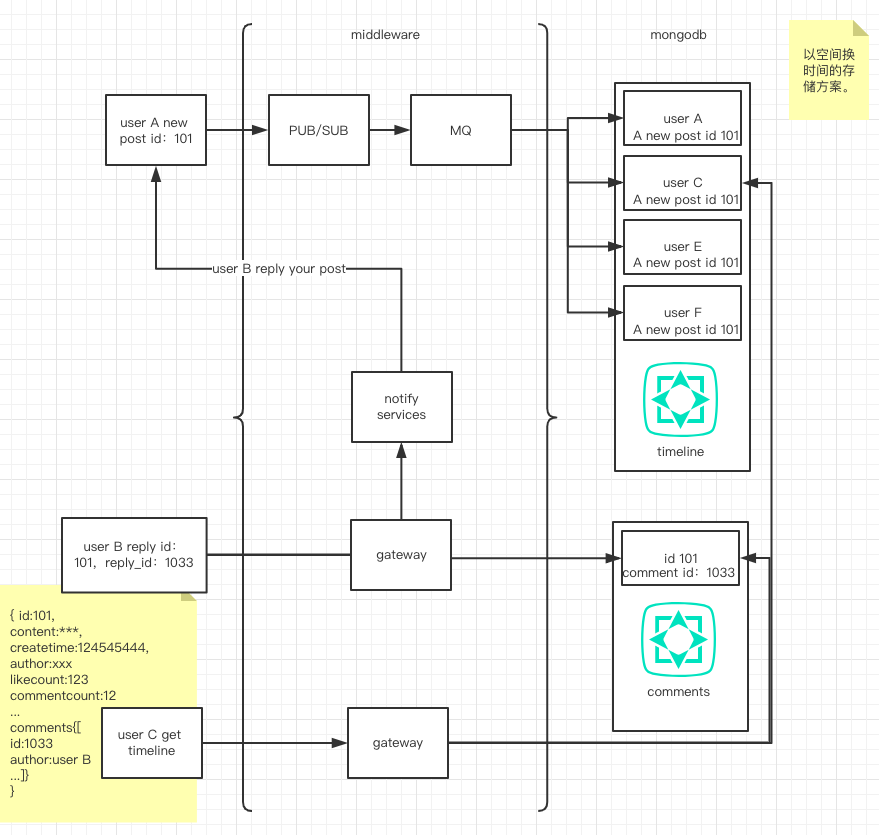
首先基于时间线而言,每个用户都有属于自己的一块存储区域,关联数据在写数据时完成。
如A发布朋友圈,会将此条记录分别写入 A,E,F,C 的时间线存储区域,每个用户只要获取属于自己的数据即可,相当程度的提高了读取效率。但是此方案将会出现大量的数据允余,这里也就是我们所说的以空间换时间的存储方案,如果此例中A有100万的粉丝,这消息副本需要100万份,即便其中大部分数据从未被读取但是这100万的存储空间是实实在在存在的,而且写数据时也会消耗一定的资源。所以这里也引用的消息序列的方案,将耗时的处理通过队列的方式处理。
针对社交关系需要注意一下,E取消对A的关注,只需要将E时间线上的有关A的数据清空掉,同理如果E关注A则需要将A时间线的数据拷贝一份存入E的时间线上。
